
This article is a sneak peek at how we ensure data quality at FINN. It explains why we monitor and alert on data quality, which data quality is essential to us, and how we implemented it via dbt. Furthermore, the article illustrates how it can leverage the distributed knowledge regarding business processes by allowing all teams to contribute to data quality.
The impact of this on FINN
- More than 70% of business logic data testing comes from people who are not part of our core data engineering team.
- 100% of all operational departments at FINN contribute data tests.
- So far, hundreds of data tests have been implemented in a decentralized (“crowd sourced”) manner within one quarter.
Background - What is dbt?
“dbt is a transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. Now anyone who knows SQL can build production-grade data pipelines.” source
Why FINN monitors and alerts on data quality.
FINN’s growth in 2021 caused challenges for the entire technical infrastructure. FINN has grown 10x in the number of signed subscriptions, and the number of employees doubled in 6 months.
During this growth, data-generating business processes change rapidly to evolve FINN’s products. This rapid development challenges data warehousing since any change in business logic needs to be considered in the data pipelines to keep analytics valid. Further, moving physical assets (cars) is challenging since many things can go wrong in the non-digital world.
To generate bulletproof analyses of the entire fleet/business state at any point in time, the data engineering team has to build a scalable/successful data platform on which analytics, data science, and machine learning teams can build.
A successful data platform ensures data quality.
One success metric of FINN’s data platform is the quality of the data we provide to other teams. Hence, we developed a technical solution to test data quality, alert data owners, track data quality over time, and enable all teams to contribute tests.
More specifically, we need to test things like:
- Basic data quality: uniqueness, nullness, types, accepted values
- Business logic: “Signed subscriptions need to have fields xyz filled”, “Cars in state x need to have fields xyz filled with”
The contribution to data quality should be decentralized.
The data engineering team shouldn’t be the bottleneck for data quality tests. The experts in business logic are part of mission-based teams. Therefore, each team should implement tests for data generated by their processes. The requirements we set for the target system.
- Req-1: Different teams implement tests in a non-centralized way.
- Req-2: Data quality tests should be easy to implement via SQL.
- Req-3: We send out notifications to corresponding teams via Slack for each test.
- Req-4: We track a history regarding test performance.
The target architecture and execution.
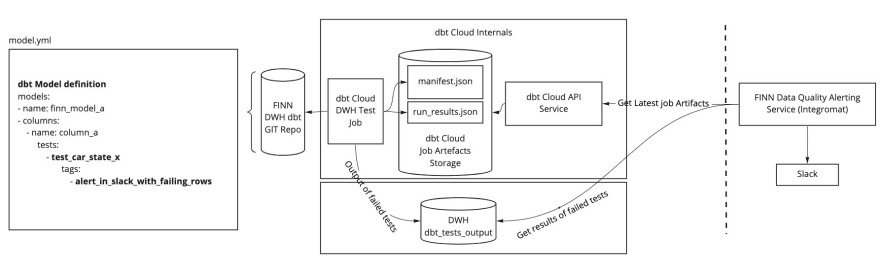
The picture shows the following components (left to right):
model.yml: yml files that are part of a git repository next to data model definitions. These files are typically used in a dbt project to document data models and run tests at column or table level.FINN DWH dbt GIT Repo: The git repository contains all of FINNs data models and corresponding documentation.dbt Cloud Internals: dbt cloud executes scheduled data transformations to create the data models (tables) (defined in the git repository). Those scheduled data transformations create job Artefacts that we fetch via dbt Cloud API.DWH dbt_tests_output: Tables in our data warehouse that contain details of failing rows.FINN Data Quality Alerting Service: AnIntegromatmake scenario that implements some logic to get job artefacts from dbt cloud, get the corresponding failing rows from the data warehouse, and forward those test results to corresponding slack channels.
The execution looks like this:
- A scheduled (hourly) dbt cloud job runs
dbt test –store-failures(running on dbt version v1.0.0). - According to the model configurations (.yml files), the tests (SQL/dbt macros) are executed on column and table levels. Job artifacts are saved.
- The Data Quality Alerting Service (an
Integromatmake scenario) fetches the job artifacts via dbt Cloud API. - The service queries corresponding results (failed rows) from the data warehouse according to the artifacts.
- The service sends failing rows to the corresponding team (Slack channel), including a resolution description.
Let’s break down the requirements step by step.
✅ Req-1: The central pillar of the system outlined above is dbt. It enables a decentralized data testing workflow (and much more).
dbt is particularly good at performing data transformations. The tooling around dbt lets our data people work in a development workflow that feels like software engineering. Other teams, which don’t focus on data engineering, are also empowered to contribute changes to data transformations. Pull requests, code reviews, data tests, and column profiling (via Datafold) ensure changes don’t break downstream data models. These features allow us to scale data (test) engineering decentralized across teams.
(Our data stack: Fivetran, BigQuery, dbt, dbt Cloud, Looker, Datafold)
✅ Req-2: Straightforward SQL to implement the tests.
The following image shows an exemplary data quality test. The configuration specifies the Slack channel to be alerted, while the description should help the corresponding team to resolve failing tests.
The SQL statement describes how to query for wrong rows. If the query returns more than 0 rows, these incorrect rows are reported in the Slack channel and resolved immediately.
| |
✅ Req-3: The Data Quality Alerting Service sends out alerts
The service (an Integromat make scenario) frequently looks for new test results via the dbt Cloud API, fetches the corresponding faulty (if any) rows from our data warehouse, and sends them to the appropriate Slack channel. The failing rows are manually checked in the data sources and cleaned up from here on.
✅ Req-4: Daily snapshots of test outputs enable tracking over time
We take daily snapshots of test results, aggregate them, and send Looker dashboards to the appropriate teams.
Thanks for reading! 💜
Feel free to reach out on LinkedIn or comment here if you’re interested in further details.
Contributors & Social Links
Felix - Data Products Manager: LinkedIn Shahbal - Data Engineer: LinkedIn Philipp - Senior Data Products Manager: LinkedIn Alex - VP Data Engineering: LinkedIn Jorrit - Tech Lead Data Engineering: Twitter, LinkedIn
Next Steps:
- Open-source the implementations
- Blogpost: The data stack at FINN
More articles by FINN engineers:
By the way, we’re hiring! (also remote/US)
- FINN on LinkedIn.
- Among the top 10 LinkedIn startups in Germany.
- Top reviews on Glassdoor.
- Tons to learn + incredible people. 🚀
Thanks to Johannes Klumpe and Gregor Albrecht for reading drafts of this!
This article was written by Jorrit Posor.