
Introduction
Make (formerly ‘Integromat’) is a highly functional low-code tool that can help you complete complex tasks, quickly. Low-code, and Make in particular, are incredible tools for rapidly creating a proof-of-concept (PoC) of new processes and iterating on existing ones. It can increase your organization’s product velocity by an unbelievable factor, especially when starting from a base of zero automation. It is the not-quite-so-secret sauce of how we at FINN managed to get to $100 million ARR in just 3.5 years.
Low-code tools are not a silver bullet, however, and come with their own set of limitations compared to traditional pro-code software development. If not built properly, and at a certain level of complexity, they can get very cumbersome to maintain and difficult to debug, find errors and fix key processes. However, through trial and error, we have found that there are some clear principles and best practices that allow you to get further using low-code than is commonly expected before needing to switch to pro-code solutions.
We use a fair bit of Make at FINN. So I thought it would be worth sharing some of the insights that we’ve collected on how to build better automations. In short: how to low-code like a pro.
In this article I want to present you with four main principles:
1. Complexity and modularization
💡 Make is visual programming; therefore using the right patterns matters. Make it modular and break complexity down into individual pieces.
2. Orchestration through API-like behaviour
💡 Orchestrate the communication in your network of scenarios efficiently with API-like behaviour and HTTP protocols.
3. Application monitoring and organisation
💡 Effectively monitoring and debugging is crucial in a low-code environment. TraceIds, standardized alerts, naming conventions and capacity dashboards help you with that.
4. Quality of life hacks
💡 Make your life as easy as possible. The DevTool, a search interface and our scenario template can be huge time savers.
I will showcase some hypotheses I have on good and bad design principles for Make, and in addition will share some best practices that we have learned so far.
Principle 1: Complexity and Modularization
Make is really just visual programming, so it’s important that you use the right patterns. The first principle that I’m reasonably confident about is: make it modular. Avoid building big scenarios. Try not to cram too much logic into one scenario, but instead split off individual scenarios to accomplish each task. Individual pieces of logic should be individual scenarios, so that you can orchestrate more of a network of Make scenarios.
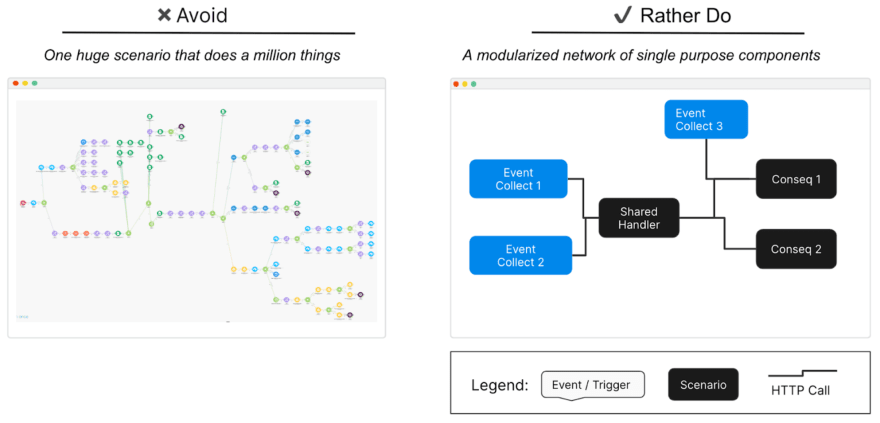 Example of a big Make scenario to avoid (on the left), and of the preferred, modularized alternative (on the right)
Example of a big Make scenario to avoid (on the left), and of the preferred, modularized alternative (on the right)
When you split logic into different scenarios that trigger each other and pass states (that is, data), then that means the scenarios will need to start with webhooks. A webhook is a URL that can receive HTTP requests, and as such can enable event-driven communication between web apps or pages. In Make, you can use webhooks such that, as soon as a certain event type occurs, that event will trigger data to be sent to the unique URL (webhook) you specify in the form of an HTTP request. That means you won’t constantly have to check another scenario, app or service for new data.
 Overview of the webhook section in Make
Overview of the webhook section in Make
Why is it best to work modularly? First, because big scenarios are incredibly difficult to maintain. Even if you’re the only person using your big scenario, after a while you will likely forget what you have done. Second, because it’s almost impossibly difficult for someone new to familiarize themselves with a huge scenario. Hence, it’s far more effective to break things down into individual pieces, and build a network of individual scenarios. That will get you a better architecture.
Just like in code, you want to break things apart into their individual components. Building as modularly and as event-based as possible is most likely the right pattern for most situations. I will further illustrate this principle with a concrete example — the “car availability calculation” — in section 2.
Principle 2: Orchestration through API-like behaviour
2.1 A network of interlinking scenarios
Once you have a bunch of individual scenarios, you need to orchestrate the communication in your network of scenarios efficiently. Arranging your scenarios in the right way saves you time, not just in building things, but also in debugging and fixing scenarios if something is broken.
 Schematic overview of a Make scenario calling another scenario and receiving a success response
Schematic overview of a Make scenario calling another scenario and receiving a success response
Let me give an example from FINN Operations. At Operations we work with compounds, which are essentially giant car processing facilities with parking lots and workshops. Compounds store our cars, mount our license plates, and stage our vehicles for final delivery to our customers. Obviously we have a lot of crucial data to share and transact upon with these providers. For example, a compound will tell us when a new car has arrived. Once we get that information, we may want to find the car in our database, and update its arrival date. You may even want to trigger other consequences, such as recalculating the availability date — because now that the car is on the compound, it can be made available for an earlier delivery date.
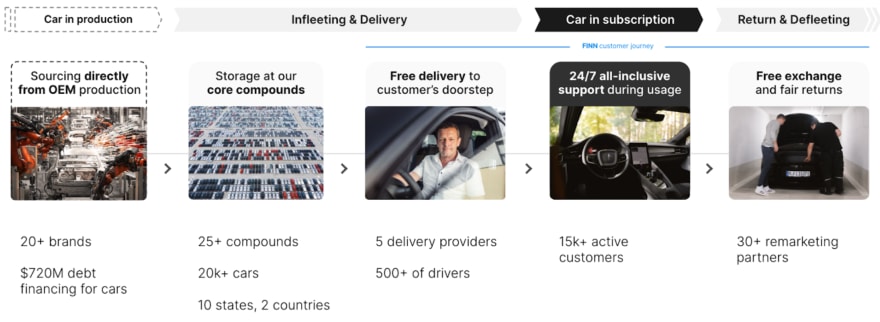 The FINN car lifecycle, from production to defleeting
The FINN car lifecycle, from production to defleeting
Ideally, when we get information that a car has arrived at a compound, we would want this information to arrive in the same way, no matter what the facility is. However, all of our partners have slightly different interfaces and data structures, so integrations work slightly differently for each compound.
Of course you could, technically, build a separate scenario for each compound that performs all of the relevant integration actions for that compound. But that would mean that if, say, you want to change some of the consequences or how you calculate the availability date, you would have to change each and every one of those scenarios.
For that reason, a better idea is to split scenarios up. That way, you can have scenarios that are more like event collectors that simply gather the data and map it into the desired data structure, and other scenarios that act like a shared handler that always does the same thing, no matter where the call came from, given that it receives a standardized payload.
Let’s say that you want to recalculate the car’s availability date whenever you receive information from a compound that a car has arrived. If you have split your scenarios apart, you could then have a compound-specific scenario that receives information about when a car has arrived. It collects the input data. Next, you could have a completely general scenario that recalculates the availability date, regardless of which compound the arrival data came from. The first, input-collecting scenario could then pass — with an HTTP call, via a webhook — the consequence to the next, date-calculating scenario. The date-calculating scenario gets the input, finds the car by its Vehicle Identification Number (VIN), recalculates the availability date, and then updates the available-from-date too.
The beauty is: you could have ten different input-collecting scenarios, each for a different compound, that then all route into this one availability calculation scenario. And this means that if anything changes in how you want to calculate the availability date, you’ll only have to update it in one place, rather than in ten different scenarios.
But what if you want to add some other consequence to the initial, input-collecting scenario that requires that the availability date has been recalculated successfully? Would that not be a problem for orchestration? This is where input validation comes in.
2.2 Always validate inputs for increased stability
When you separate your scenarios, you will sometimes still need to send data back and forth, to be sure that a certain scenario actually ran successfully. Before running a scenario, we want to check that all the required input variables are included in the payload. Additionally, when passing back data between two scenarios, we want to make sure that the response payload is in a standardized format and that the called scenario has actually run successfully. In case it did not run successfully the called scenario needs to communicate that information and we need to catch and handle that error in the calling scenario appropriately.
For example, if we get an update from a compound that a car has arrived, but this car doesn’t actually exist in our database, then the scenario that uses the car_ID to recalculate the car’s availability date will produce an error. In turn, any other scenario that relies on the recalculated availability date should be made aware of that error. So, if an expected variable car_ID is not passed for a certain scenario, then you can return a HTTP 400 status code, and in the body, you can say that the response code is 400 and return an error message, for example "error”: “data missing [car_id]".
If you build your scenarios like this, then whoever calls the scenario immediately knows why things failed. Whenever you have a webhook response, always provide:
- a response code1
- a message
- data
While the data can be null, the response code and message should always be filled.
We want to avoid errors. Besides, the webhook URLs in Make are public, which means that technically anyone with an internet connection could trigger them at any time if they knew the URL. So at any point where you expect an input from a previous module, you should have a filter that checks if you in fact have that variable. Additionally, you can increase the stability and security of your scenario by requiring a password to be passed. This basic authentication is analogous to how pro-code APIs use API keys and tokens to authenticate API calls. A good way to manage these different API tokens and avoid hard-coding them in all scenarios is to use Make’s new custom variables feature. This allows for a more streamlined maintenance of these tokens and allows you to easily swap the tokens in case they become compromised. This is analogous to using env variables in a pro-code CI/CD pipeline. With your filter that checks for the presence of a certain variable, if you don’t find the variable, then you return the relevant message and response code. Building in such basic validation will save you significant time in the long run and help assure peace of mind that your scenarios are secure.
2.3 Security through API keys
A best practice is to reject any call that does not have an API token specified. Make webhooks are basically public, anyone could use the web hook link. That means you want to be sure that your scenario is not used by people that might not know how to use it. So you can reject them if they don’t have the right password. It just adds another layer of security.
So we want most scenarios to be modular, orchestrated, and we want to validate inputs. But how do you keep tabs on such an orchestrated network of scenarios? This is where we turn to application monitoring.
Principle 3: Application monitoring and organisation
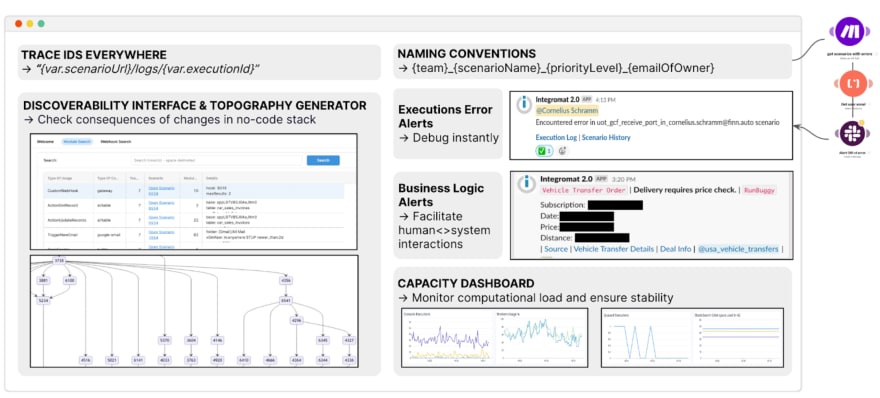 Overview of some key Make best practices for application monitoring (the execution log in this graphic is identical to the trace ID discussed in what follows)
Overview of some key Make best practices for application monitoring (the execution log in this graphic is identical to the trace ID discussed in what follows)
One of the bigger downsides or limitations when using Make, compared to traditional pro-code services that have advanced logging frameworks and comprehensive test coverage, is application monitoring. If left unchecked, the sprawling, ever-expanding and interlinked network of automations can quickly become a black box where no one really knows what is going on and how things work. Thankfully, there are very powerful tricks and best practices to remedy a good portion of these issues. One such best practice that everyone should be aware of is application monitoring. How we approach application monitoring with our networked scenarios has several aspects, and can be set up as follows.
3.1 Use naming conventions
Using naming conventions for naming your scenarios, and sticking to those conventions, will help save you many headaches in the long run. At FINN we use a rulebook that specifies our naming conventions for Make scenarios, so that everyone knows what to call a new scenario. This includes rules such as ‘Always put the team in front of the title of your scenario’, ‘Always include the email address of the DRI (Directly Responsible Individual) at the end of the scenario name’, and ‘Use draft_ when you start building a scenario and is not ready to be turned ON’. Naming conventions are also important for alerting.
3.2 Use standardized alerts
The naming conventions discussed above significantly impact how we manage our error notification system. We utilize regular expressions to extract relevant information from HTML-formatted alert emails and swiftly identify the responsible person and tag them via Slack. FINN is a very Slack-heavy organization and we use Slack a lot for human-system interactions. We have a template for how we format Slack alerts, because it just makes it nicer to work with. Our template for Slack alerts for Make operations also always includes — you guessed it — the trace ID, plus a link to any other useful resources. Using standardized logs, alerts, and passing trace IDs everywhere will save you so much time in the long run.
3.3 Pass a trace ID
Whenever we make a call from one scenario to another, we pass the execution log — so, the URL of the scenario combined with the execution ID, {scenarios_URL}/log/{execution_ID}—as a string. Passing this execution log allows you to track and store the different executions in Make. On the one hand, if you call another scenario you will see the execution ID in the headers, and you can use that URL to check out which execution failed, or produced an unexpected result. Conversely, for the receiving scenario, it tells you which scenario it was called by, and therefore instantly trace where calls are coming from. Always having instant access to the calling or responding scenario logs can save you hours in debugging time and prove especially useful in ‘moments of truth’ where something is really going awry and quick action is needed. No matter how skilled you are, things will inevitably go wrong from time to time. Debugging effectively is crucial to building a stable automation landscape which is why we are religiously including trace IDs in everything we build.
Let’s jump into an example. Say that we’re looking at a call scenario that calculates the availability of a car. In the beginning we define a bunch of return headers, like a JSON string that contains both the fact that we’re returning a JSON, and that we are returning the {scenarios_URL}/log/{execution_ID}. That means that whenever you open a scenario execution, you can find this {scenarios_URL}/log/{execution_ID}. Sending these logs allows you to jump back and forth very easily.
In short, we want to have the trace IDs literally everywhere. So: whenever you call another scenario, you pass the trace ID. Whenever you respond to a call from another scenario, you pass the trace ID. At FINN, passing the trace ID in your calls is part of our ’non-negotiable rules to follow’. If there’s one thing to take away from this article: pass the trace ID.
3.4 Provide webhook responses
In addition, we want to use webhook responses to tell a calling scenario whether something worked or whether there was some kind of error (and, in that case, return an error code). These are classic HTTP responses. Plus, this is also how any API communication protocols work: you give a HTTP 200 status code if everything was good; you return a 500 status code if there was a server error, or 400 if it was a bad request. For example, in case that you request a car_ID that doesn’t exist, you should return a HTTP 400 status code, because it was a bad request.
3.5 Capacity monitoring
At FINN we also have a Make capacity monitoring dashboard. A big shout-out to my colleague Delena Malan, who recently built this. You can see this as a command center-view of what is happening currently in our automation landscape.
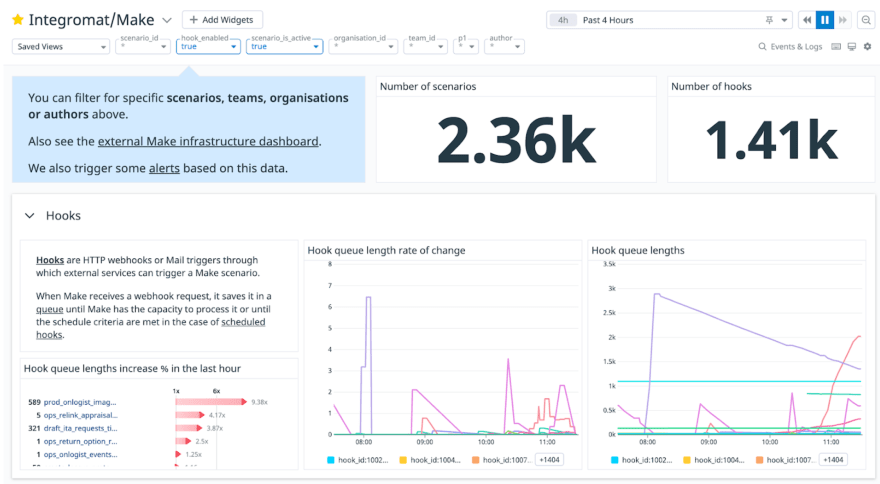
FINN’s Integromat/Make capacity monitoring dashboard
Keep in mind that, like anything in life, automation compute-time is not free. We have certain limits on how much execution and computational power we use. If you build a scenario that spams another one with 50,000 records and there are 50,000 scenario calls in the queue, then you will block other processes.
In the past, we’ve occasionally had instances when a customer was temporarily not able to check out, because our Make was over-capacity and didn’t have any more compute time. So always keep those computational constraints in mind. A capacity monitoring dashboard helps you to see if there is a spike in, let’s say, the queue length, or the rate of change, or the number of incomplete executions. It’s a useful thing for everyone to look at, especially if you’re wondering: Why is Make so slow? Why is my stuff not running?’ Such a dashboard will help you find out what scenarios are causing it, allowing you to remedy it quickly. It has already helped me a lot of times.
These were my three main principles for low-coding like a pro. Let me now turn to some best practices that can improve your Make quality of life even further.
Principle 4: Quality-of-life hacks
Here are some small quality-of-life improvements that I’ve learned over time. They can save you a bit of time here and there, and make you want to pull your hair out just slightly less frequently.
4.1 Make search tool
My colleague Dina Nogueira built a very cool and useful Make search tool. Consider how, in a code editor, you can do Ctrl+F to find some string in your code. The search tool does exactly that, but then for Make scenarios: it goes through all the scenarios, tries to find the string that you’re searching for, and will just output a list of scenarios that reference this string. So whenever, let’s say, you need to adjust all the scenarios that have car_ID in it, then you can use a search tool like this, and it will produce a list for you. From that list you can just click directly on the links. The search tool can be especially useful when making data model changes. As you are more likely than not exposing your database’s schema directly when building backend processes with Make, the blast radius of changing the data model can be potentially very big, as all scenarios that rely, say, on a column that got renamed will break. The search tool will allow you to fix things quickly.
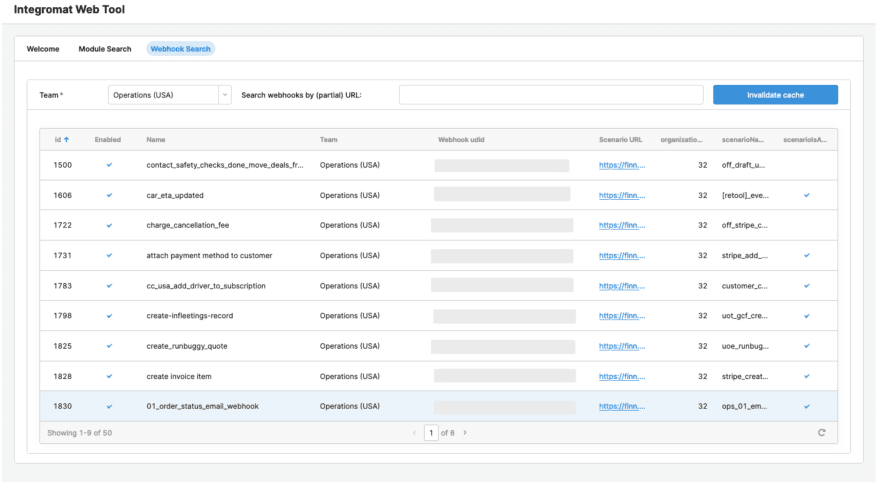
Our FINN custom-built Integromat (Make) search tool
4.2 Integromat (Make) DevTool
Another useful thing is the Integromat (Make) DevTool, which is a Chrome browser extension. The DevTool allows you to have a more detailed view of the things that are actually happening in the background. For instance, sometimes some apps on Make give you unhelpful error messages. They just will tell you: some error occurred. However, with this browser extension installed, if you open the log, and you open the console, you can find more details about what the exact response was from the API that produced an error. Plus, you can do a bunch of other cool stuff. It’s a pretty powerful tool.
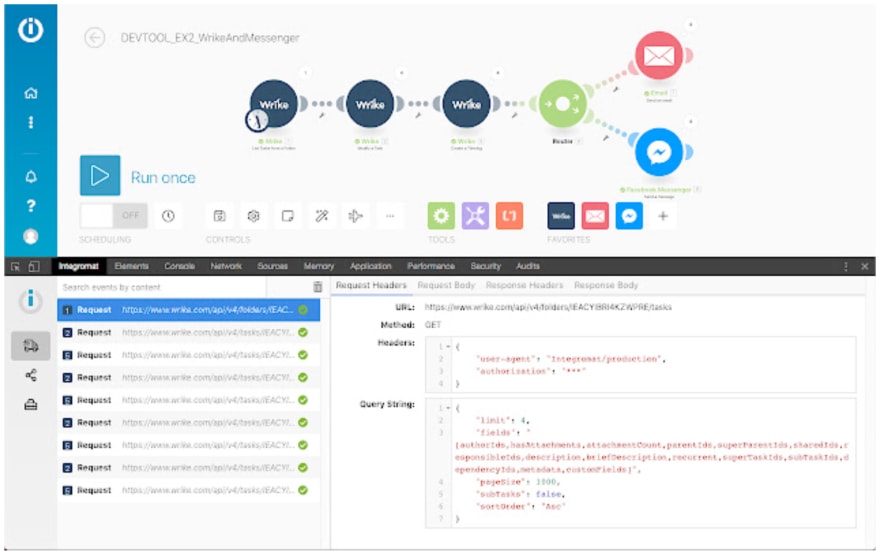
The Integromat (Make) DevTool
Use the DevTool carefully, though, because you can also screw some things up with it. But for debugging purposes, it can save you a lot of time. If you’ve found debugging Make scenarios cumbersome in the past, this is a useful quality-of-life hack.
4.3 Use a template 😉
Here’s a cool thing: I’ve built a template that has all of the relevant base structure, and basically gives you many of the checks discussed in this article for free.
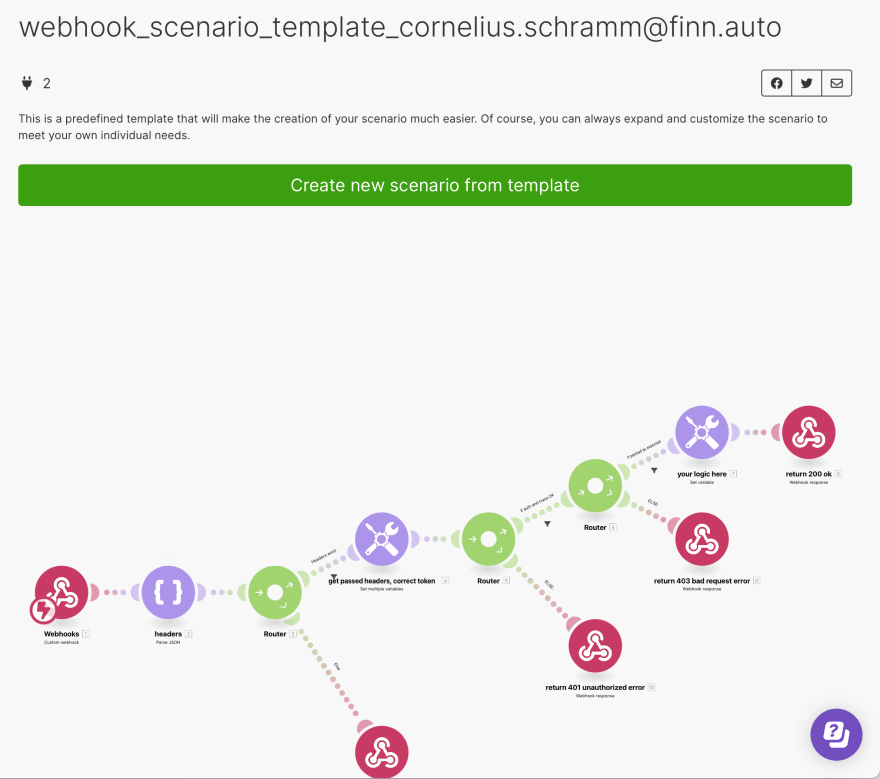
The scenario template with basic checks and validation steps built-in
With the template, you can create a new scenario just as fast as you would if you did it from scratch: you just click ‘clone’, you push, add a new webhook, and make sure that the webhook setting includes ‘retrieve HTTP headers’. You will need to replace the dummy variables with your own variables, set the correct headers and methods, and then you can just put whatever additional logic you need in there. Then you have a new scenario with all of that logic, checking, and validation for free. Trust me, this will save you so much time and pain in the future.
–
That’s it! I hope these Make principles and quality of life hacks will be useful to you. If you have questions, feel free to reach out or put them in the comments. Follow FINN for more low-code content and events :)
This article was written by Cornelius Schramm, with contributions from Chris Meyns.
The reason you also want to pass the response code in the body of the response, in addition to sending the actual HTTP code, is due to a small particularity of how Make webhooks work. In case a webhook is attached to an inactive scenario, you still get back a 200 response when calling it, even though the scenario itself did not run. From the perspective of the calling scenario, you obviously want to make sure that the scenario you called actually ran successfully (rather than it just being inactive). When using the filter
{{if(5.data.response_code = 200)}}you can ensure that the called scenario actually ran before you proceed. This is especially important if the calling scenario relies on data passed back from the called scenario. It is the principle of validating inputs before proceeding at work. ↩︎