
Building proficient data teams and providing them with the right technical tools is crucial for deriving analytical insights that drive your company forward. Understanding the skills, technologies, and roles at play forms an essential part of this process.
This post offers an overview of these key components shaping a ‘Modern Data Stack’, which you can use to guide your hiring and strategic planning.
Context and Background
The strategies shared in this post are drawn from a successful initiative at FINN, a German scale-up. The approach enabled the data teams’ significant expansion from a small team of three data engineers to a comprehensive team of 35 practitioners over the course of two years. Concurrently, the company’s size quadrupled from 100 to 400 employees.
Integrating data into FINN’s culture and processes is significant: we utilize over 600 dashboards; 58% of our company uses Looker weekly, spending an average of 90 minutes each week on the platform. This level of engagement translates into nearly half a million queries weekly.
While the insights presented here can also benefit larger organizations, they are primarily based on the experiences and challenges encountered during FINN’s growth trajectory.
The technology focus of this post is on a batch-based technology stack while streaming technologies are not considered.
From Raw, Fragmented Data to Analytical Artifacts
When working with business data, your goal is analytical artifacts: key performance indicators (KPIs), dashboards, insights, and a comprehensive understanding of your business—all derived from your data. You most likely already possess raw source data in the SaaS tools you use (like HubSpot or Airtable) or in your databases.
So, the pertinent question is: what transforms your source data (shown under ‘Data Sources’ in the top part of image 1, in yellow) into these insightful analytical artifacts (shown under ‘4. Analytical Artefacts’ in the bottom part of image 1, in purple)?
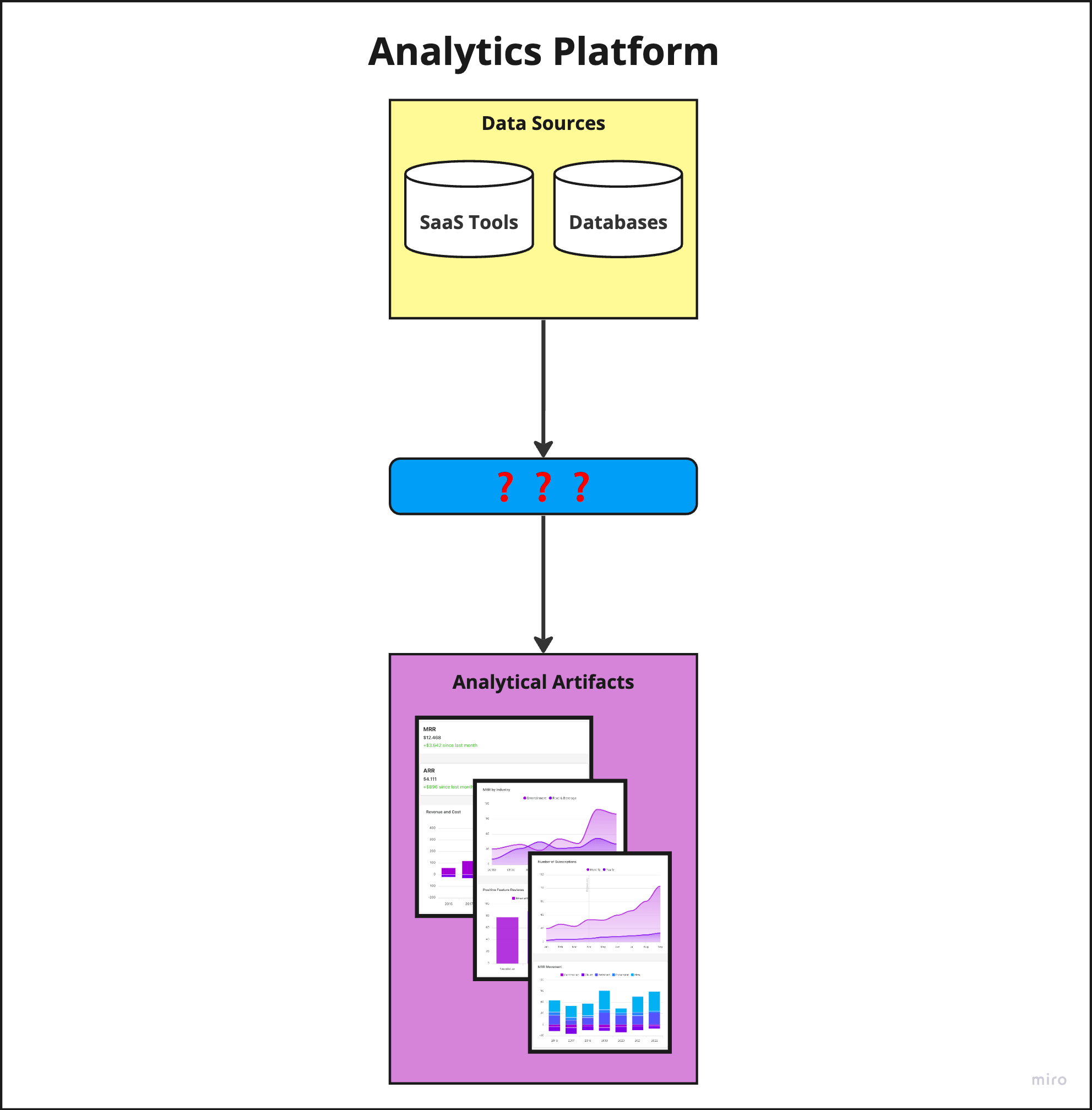 Image 1. Overview of an analytics platform. What gets you from data sources to analytics artifacts?
Image 1. Overview of an analytics platform. What gets you from data sources to analytics artifacts?
Extract, Load, Transform, Analyze: The Pathway to Analytical Artifacts
Transforming your source data (at the top of image 2, in yellow) into analytical artifacts (at the bottom of image 2, in purple) involves a sequence of technical steps (in the middle of image 2, in blue, numbered 1-3).
Data is systematically extracted from various sources and maneuvered through transformations (changes) and technical components. It eventually emerges as part of the analytical artifacts.
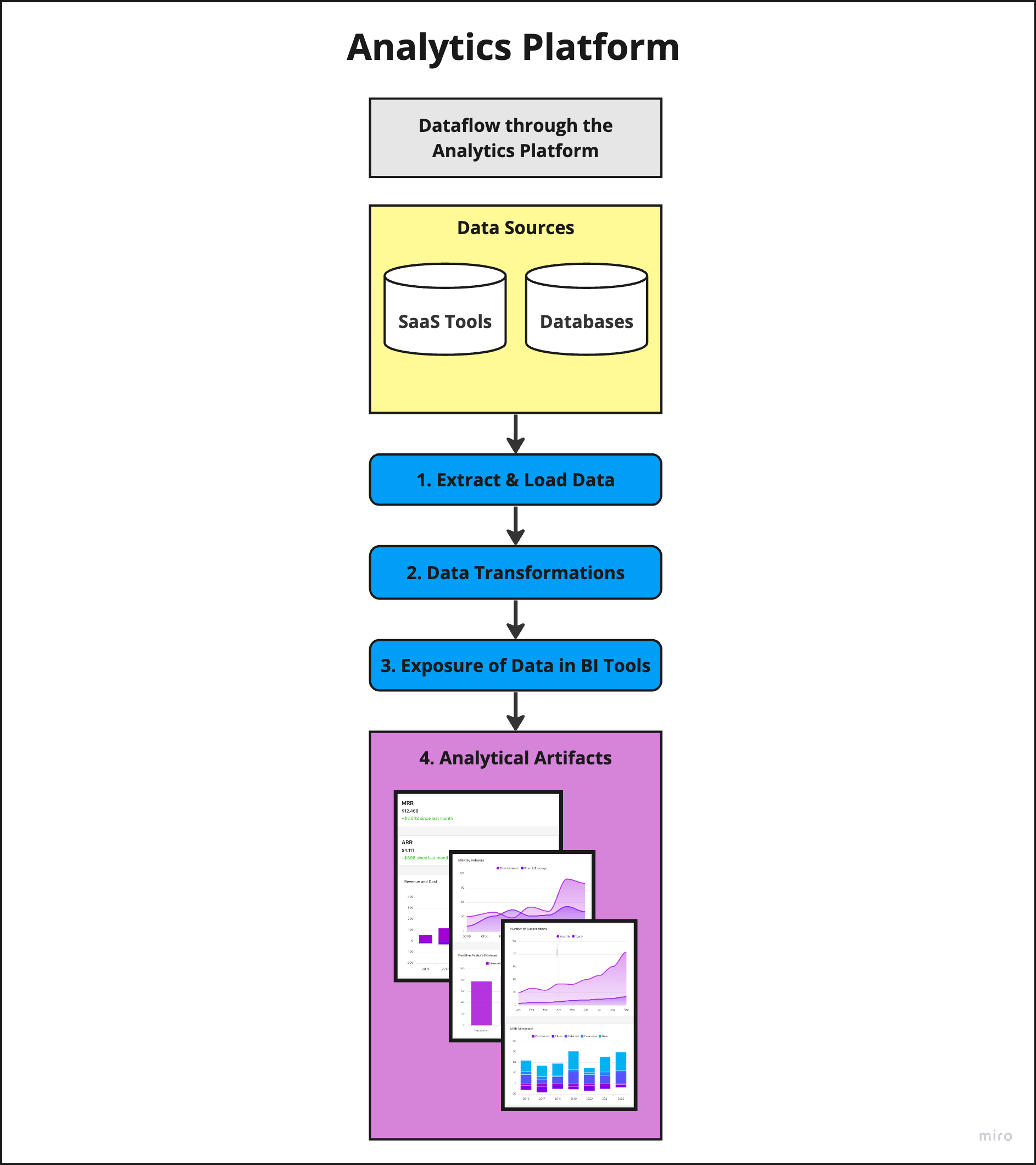 Image 2. Overview of the technical steps of the dataflow through an analytics platform, moving from source data to analytical artifacts.
Image 2. Overview of the technical steps of the dataflow through an analytics platform, moving from source data to analytical artifacts.
Data professionals often describe this as “data flowing” from sources through data pipelines into analytical artifacts. The arrows in the diagram signify this dataflow, highlighting the key operations involved (in blue):
Extract & Load Data: This stage involves copying data from data sources to a data warehouse. The data is systematically duplicated from every relevant source, copying it table-by-table to a data warehouse (such as BigQuery). Technologies utilized include ingestion providers (SaaS tools) and custom-built data connectors. These tools extract and transfer data from various sources to a data warehouse. This process follows a specific schedule, such as loading new batches of data into the data warehouse every hour.
Data Transformations: This phase involves modifying and integrating tables to generate new tables optimized for analytical use. Consider this example: you want to understand the purchasing behavior of customers aged between 20-30 in your online shop. This means you’ll need to join product, customer, and transaction data to create a unified table for analytics. These data preparation tasks (e.g., joining fragmented data) for analysis are essentially what “Data Transformations” entail. At FINN, technologies utilized in this phase include BigQuery as a data warehouse, dbt for data transformation, and a combination of GitHub Actions and Datafold for quality assurance.
Data Exposure to BI Tools: This stage involves making the optimized tables from Step 2 accessible company-wide. Many users across your organization will want access to these tables, and they can obtain it by connecting their preferred tools (such as spreadsheets, business intelligence (BI) tools, or code) to the tables in the data warehouse. Connecting a data warehouse to a tool typically requires a few clicks, although depending on the context, it can sometimes involve more configuration or even coding.
Creation of Analytical Artifacts: The final step involves the creation of analytical artifacts within these BI tools (or code). This work is typically done by BI users, analysts, and data scientists. These professionals take the accessible tables and transform them into actionable insights. They may create dashboards for monitoring business processes, produce KPIs and reports for strategic decisions, generate charts or plots for visual understanding, or even construct advanced predictive models for future planning.
This process not only unveils valuable business insights hidden within the data but also delivers information in an easy-to-understand format that supports informed decision-making across various levels of the organization.
Essential Hard Skills Along the Dataflow
Let’s now have a look at the hard skills that are required in terms of our analytics platform.
Different types of work are required along the dataflow, and hence the hard skills change depending on the stage of the dataflow. These skills, along the yellow vertical lines on the left side of image 3, are crucial to managing the different stages of the process.
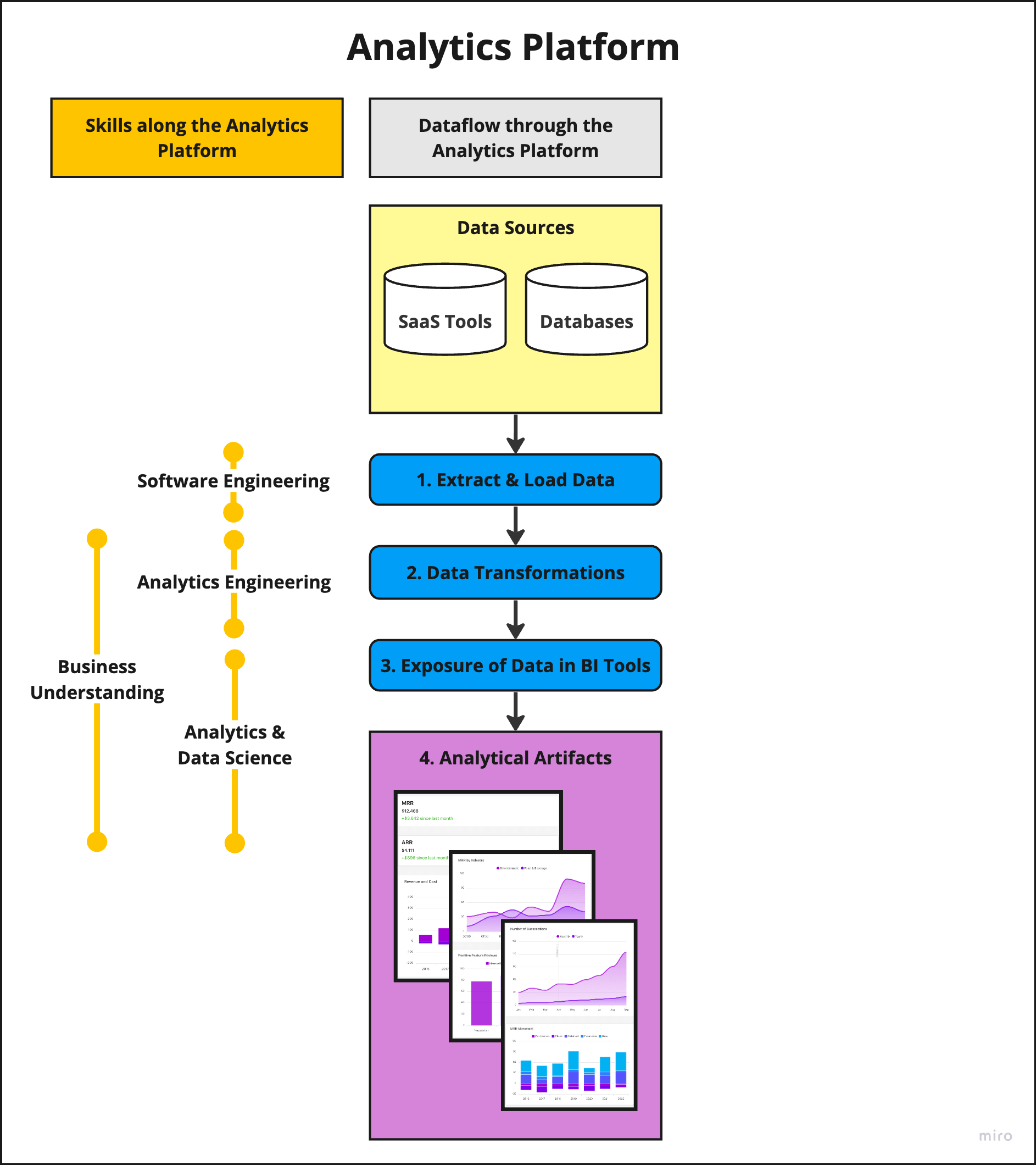 Image 3. Overview of the skills that are required to work with data in the different parts of the analytics platform.
Image 3. Overview of the skills that are required to work with data in the different parts of the analytics platform.
Let’s take a closer look at what the different skills mean in the context of our analytics platform.
Software Engineering: Implementing data connectors in-house, which extract data from sources, requires writing software.
This skill is particularly crucial for the initial step of making data available in the data warehouse. It also requires cloud and infrastructure knowledge, as the software must operate in the cloud, follow a schedule, and consistently extract/load new data.
Analytics Engineering: Predominantly SQL-focused when working with dbt, this skill involves transforming raw data from sources into tables useful for analytics—a process labeled ‘analytics engineering’.
At FINN, this primarily takes place within the data warehouse (BigQuery) using a data transformation tool (dbt). From a technical standpoint, raw tables are cleaned, combined, filtered, and aggregated to create many new tables for analytics. A common practice to make tables analytics-ready is “dimensional modeling”.
Analytics & Data Science: This refers to utilizing transformed tables and extracting insights from them.
Analytical artifacts created at this stage include dashboards, KPIs, plots, forecasts, etc.
Business Understanding: As data is the product of a business process, understanding these processes is crucial.
Business understanding is required from the data transformation phase right through to the creation of analytical artifacts. Without business understanding, effectively transforming raw data into insights would be impossible.
For example, accurately counting the number of converted leads requires understanding what qualifies as a ‘converted lead’ (considering fraud cases, credit checks, and so on).
Navigating the Implementation and Scaling of a Data Teams
We’ve explored the process of transforming source data into analytical artifacts. Now, we face the most critical question: how can you efficiently integrate this mix of people and technology?
Addressing this question involves various technical and non-technical dimensions, which, if not properly managed, can lead to costly decisions, inefficient data teams, and delays in delivering insights.
Regrettably, the answers to these technical and non-technical questions change as your company grows. The journey of onboarding your initial five data practitioners differs from the leap from 30 to 35 practitioners.
How FINN Navigates the Complexities of Scaling
Understanding your organization’s specific needs and aligning those with your team’s structure and technical architecture is critical.
The complexities, inherent in technical and non-technical aspects, aren’t static; they evolve as your company grows. Thus, it’s important to remember that the process is dynamic - transitioning from a small team of data practitioners to a larger one, or even adding just a few more members, can change your operational dynamics.
Let’s delve into the experience at FINN. As we navigated the process of building and scaling an analytics platform across multiple data teams, we discovered that our journey encompassed distinct scaling phases. Each phase introduced its challenges and requirements, necessitating different approaches and shifts in team dynamics and responsibilities. Image 4 highlights the responsibilities of roles, which are constantly changing.
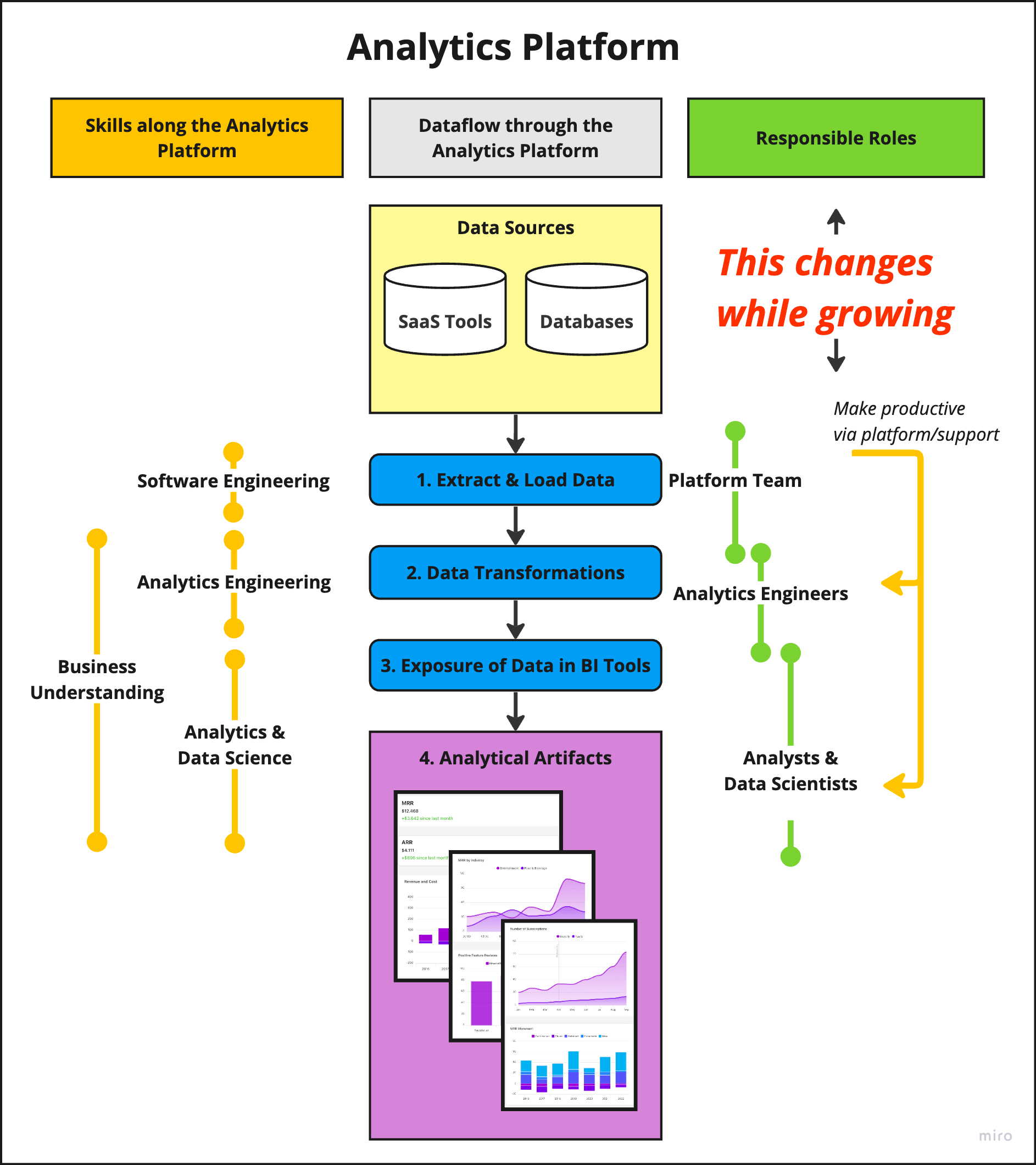 Image 4. Overview of the roles required to work with data in the different parts of the analytics platform. The responsibilities of roles change while growing data teams. Initially, a small platform team has to cover data tasks end-to-end, from raw data to analytical artifacts. While growing, the roles can specialize in specific areas of the analytics platform.
Image 4. Overview of the roles required to work with data in the different parts of the analytics platform. The responsibilities of roles change while growing data teams. Initially, a small platform team has to cover data tasks end-to-end, from raw data to analytical artifacts. While growing, the roles can specialize in specific areas of the analytics platform.
Let’s explore FINN’s scaling phases in more detail.
Setting up the Analytics Platform Team: This initial stage is focused on establishing the core analytics platform team, laying down the technical infrastructure, and delivering initial insights to stakeholders. The platform team works end-to-end, meaning it picks up raw data and delivers analytical artifacts likes dashboards to stakeholders.
Onboarding Other Data Teams: The second phase entails the integration of additional data roles (like analysts, analytics engineers, and data scientists), referred to as “data teams”. They deliver insights using the analytics platform but don’t form part of the platform team. Their introduction shifts the dynamics as they take over previously built analytical artifacts and BI-related tasks and share data transformation responsibilities.
Specialization: In the third phase, the platform team focuses on platform improvement and enhancing the data teams’ productivity. Other data teams, meanwhile, specialize in specific business areas and data transformations. The extent of this specialization is highly context dependent and aligns with the company’s unique requirements.
Navigating Conway’s Law: When scaling, a company may find itself in a phase filled with considerations around the balance of centralization vs decentralization, both from a technical setup perspective and from a team structure perspective. Informed by Conway’s Law—which suggests that a team’s structure should mirror the desired technical architecture—a company may seek to align its teams accordingly. For example, this could mean centralizing communication patterns when stability is needed in centralized, shared parts of the data pipeline. Keep in mind that each step towards centralization may secure some benefits at the cost of potentially surrendering those derived from decentralization, and vice versa.
Thus, navigating these trade-offs to find the sweet spot can be an intricate journey.
Conclusion
Understanding the necessary skills, roles, and technologies is crucial in the dynamic and complex journey of building and scaling effective data teams. The transformation of raw data into insightful analytical artifacts requires a broad set of hard skills and deep business understanding.
The journey through different scaling phases—initial setup, onboarding, role specialization, and Conway’s Law—will demand adaptability and resilience.
This blog post provides a foundational understanding of these concepts, and we hope it serves as a valuable guide for your scaling journey. For more deep dives into these topics, consider subscribing to our blog. Future posts will dive deeper into “Scaling Phases”.
Happy scaling! Thanks for reading!
Thanks, Kosara Golemshinska and Chris Meyns, for recommendations and for reviewing drafts!
This post was originally published on Substack.
Appendix: Pivotal Dimensions
This is an overview of pivotal dimensions when scaling data teams. The primary aim is to provide a broad picture, while the secondary objective is to encourage you to subscribe to this blog. Doing so will ensure that future in-depth discussions on these topics (for example, ‘Modern Data Stack: Deep Dive into Pivotal Dimensions’) land directly in your inbox. 😊
Phase Goals: What goals should be set for each data team to generate business value in a given scaling phase?
Technology: Does your technology empower data practitioners, or does it hinder them due to improper usage patterns, knowledge gaps, lack of support, or technical debt?
(De)centralization Trade-offs: What are the implications of fundamental decisions regarding “decentralized vs centralized” data teams in your organizational structure and technology architecture?
Technical Debt: How can you mitigate the creeping technical debt that could hamper and gradually slow progress?
Policy Automation: How can you implement policies (such as programming standards) with decentralized data practitioners?
Critical Skills: What skills are necessary for each scaling phase?
Communication Processes: How many people, on average, need to be involved to deliver insight to their stakeholders?
Knowledge Transfer: Are knowledge silos emerging, creating bottlenecks? How can you efficiently distribute required business knowledge, especially when business processes evolve?
Support Culture: How and when should you foster a support culture? Are data practitioners blocked due to a lack of information that others may have?
Resource Alignment: How can you manage effort peaks? Can you flexibly reassign data practitioners between business units?
Engineering <> Data Alignment: How can you guarantee that changes to data sources, business processes, or technical aspects (such as a schema) don’t disrupt your downstream analytical artifacts?