At FINN, we strongly believe in the principle of do it, do it, automate it. If you find yourself doing something manually twice, you should find a way to automate the process. This holds just as true when it comes to the precious details of invoices and financial document processing. Within the FINN Finance team, we’ve recently started using a platform called Rossum that helps us improve the automatic optical character recognition (OCR) of documents. But to understand why Rossum is so helpful, let’s first dive into the problems you’ll frequently run into with traditional OCR tools.
Problems with traditional OCR
Consider the sheer variety of invoices we receive on a daily basis:
 Snippets from different invoice PDFs with different formats for the total amount due
Snippets from different invoice PDFs with different formats for the total amount due
In these invoice PDF snippets, the fields indicating the total amount due are very different from one another. Sometimes the currency is specified in euros, in other cases it’s in dollars. Some invoices speak of ‘Total amount’, or ‘Balance due’, while still others use ‘Brutto’. The formatting is all over the place, which wreaks havoc on regex-based OCR.
For humans, such variation is relatively easy to read. When a human looks at this, they should not have much trouble distinguishing what is what. A human would usually skim the documents and see that invoice number is in one place, the date in another, and so on. In skimming a document like that, we know to expect localized data (i.e. the total should be somewhere under the itemized table).
Humans can also make quick decisions. For example, when you know dates only come in a certain format, then you can easily pick up cases where there’s something wrong with an invoice, such as where the due date of the invoice appears to be before its issue date.
But such an approach is less straightforward for a machine. And this is exactly where traditional OCR systems can face challenges. When there is lots of variation in the input formatting, traditional OCR might give you accurate data, sure. But it’s not obvious that in all cases it will find exactly what you’re looking for. When you’ve got tens of thousands of invoices to process, that’s not the sort of issue you want to run into. So how did we at FINN solve this problem?
Superpowered OCR with machine learning
Enter: Rossum. Rossum is a platform for, as they call it, ‘intelligent document processing’, that automates the processing of variable documents. And ‘variable documents’ here means that you are dealing with documents that have very similar data (such as data for the total amount due), but in totally different formats (different labels, currencies, date formatting, and so on). Rossum uses machine learning to improve and speed up the processing of such documents. And it does so by trying to approach these invoice documents a bit more the way a human might. So how does that work?
At FINN, our use case is processing incoming invoices. To do this, we first set up a schema for all the data points that we want to collect from the invoice, and train the relevant model. After that initial training, by and large it can run entirely automated (though we might improve the training once in a while). Next, we set up our email automation so that we process invoices as soon as we get them. We can define a confidence score (with options ranging from 0 to 1), which indicates the degree of confidence of the AI engine that it has correctly identified the location and text of a field. For instance, if you set the required confidence score at 0.8 (80%), then when the system is able to meet that threshold, the whole OCR processing runs automatically and no human will have to look at it. Only when the system is not able to meet the selected accuracy levels, it will send you a notification, so that a human can still review it.
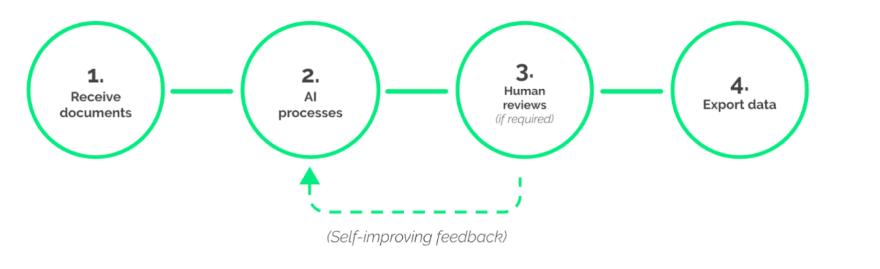 Workflow with Rossum for automating incoming invoice processing
Workflow with Rossum for automating incoming invoice processing
Two parts make the process especially fun. First, because Rossum uses machine learning, the system progressively gets better. If you have a field that initially needed regular reviews, then once you get enough manual reviews, the system will learn to detect that field. As a result, the next time we see a similar kind of case, it may very well hit the required accuracy levels and automate the entire process. That’s one huge advantage of using Rossum.
The other fun part is data validation. It is super easy to set things up to validate a range of data. For example, to check that the supplier exists, that the supplier’s International Bank Account Number (IBAN) is in such-and-such format, or even to catch plain errors. We once had a supplier send us an invoice dated the 31st of June, which is an impossible date. Due to proper data validation, it’s very easy to catch that.
Traditional OCR does not work like this at all. But such an approach is very intuitive to humans, and Rossum is trying to approximate that.
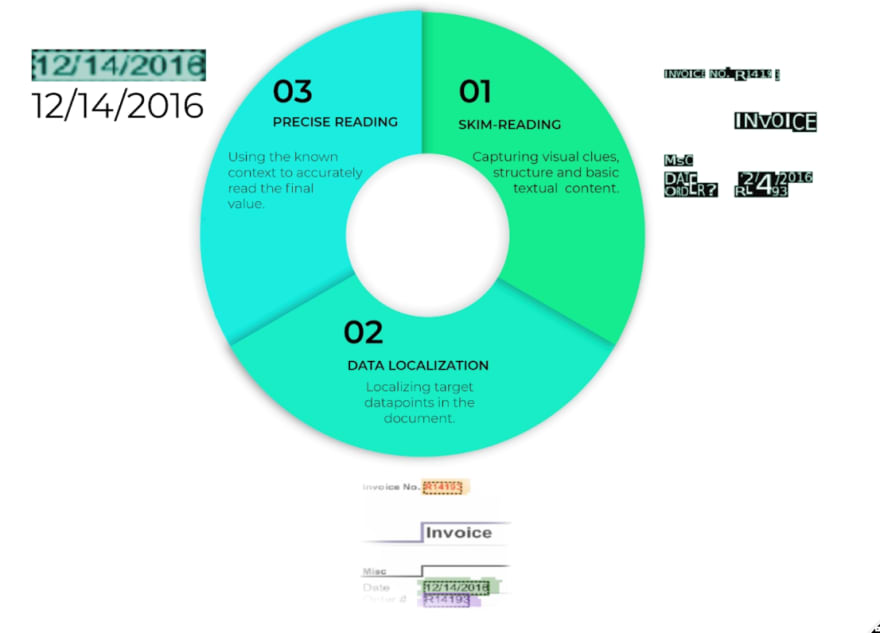 The stages of skim-reading, data localization, and precise reading that Rossum uses
The stages of skim-reading, data localization, and precise reading that Rossum uses
Customization and training your own engine
Different organizations will have different needs in terms of document processing. At FINN we work with car subscriptions, so it’s often crucial for us to find things such as the car’s license plate, or the Vehicle Identification Number (VIN) on the invoices. Rossum has a very good generic engine that we can use straightaway. This already helps us find many of the relevant issues. But in addition, you can also purchase an engine that you can train for customized options that are specifically relevant to your organization. So at FINN we decided to add things such as the VIN as specific options to the training process, to tailor it to our specific needs.
The Rossum website also offers a bunch of different settings for customization. It also allows us to distinguish between different types of documents to process, such as invoices, or speeding tickets. Or you also have settings to specify what kind of language you’re mostly working with.
Language processing is interesting. Many conventions in financial documents differ between languages, or from region to region—think of decimal separators, or date formats. You would think that that should result in quite some difficulties with OCR-ing the invoices? Well, not really. So far at FINN, we haven’t had to train separate models for, say, German versus US English invoices. Rossum supports a ton of customization options: it already covers most languages that use a variation of the Latin script, and support for Japanese and Chinese language documents is currently in beta. At FINN, we are regularly processing invoices with a range of different formats.
In terms of really taking things further, Rossum even allows you to add extensions with your own logic. For example, we may want to match the supplier name found on an invoice to the list of suppliers already known to FINN. But in case of a new supplier, you’re obviously not going to find a match. To solve this, we built an app with our drag-and-drop internal tools building system Retool, that we hooked into the Rossum web interface. So with a single click you can go straight from Rossum to our dedicated Retool app and insert the new supplier.
Going yet further, we already have a list of cost centers that we use on our finance management tool. Once the system recognizes the supplier name, we can also match this automatically to the cost center. Once matched, we can export and save all the information in our own database and upload it directly to our SaaS Finance Tool. Ideally, then, once it’s all trained, the entire process is mostly automated — it’s all super smooth for the user.
Alternatives
We did evaluate a few other OCR tools like Nanonets and Super.AI. Rossum caters well to both non-devs and devs. The UI is very easy to use, and they have great API Docs. The options for custom extensions using Lambdas or Webhooks open up Rossum to great extent, which makes up for some missing features. We have built our own extensions for data validation, detecting multiple invoices in a single pdf, removal of irrelevant pages, etc.
So that’s how we at FINN are using Rossum to automate and speed up our financial document processing.
Have you had any challenges with financial document processing? Let me know in a comment how you solved them!
Resource
Written by Chris Meyns (Technical Writer) and Gazala Muhamed (Software Engineer)